Google has been the Firefox global search default since 2004. Our agreement came up for renewal this year, and we took this as an opportunity to review our competitive strategy and explore our options.
In evaluating our search partnerships, our primary consideration was to ensure our strategy aligned with our values of choice and independence, and positions us to innovate and advance our mission in ways that best serve our users and the Web. In the end, each of the partnership options available to us had strong, improved economic terms reflecting the significant value that Firefox brings to the ecosystem. But one strategy stood out from the rest.
In Russia they’ll default to Yandex & in China they’ll default to Baidu.
One weird thing about that announcement is there is no mention of Europe & Google’s dominance is far greater in Europe. I wonder if there was a quiet deal with Google in Europe, if they still don’t have their Europe strategy in place, or what their strategy is.
Added: Danny Sullivan confirmed Google remain the default search engine in Firefox in Europe.
Google paid Firefox roughly $300 million per year for the default search placement. Yahoo!’s annual search revenue is on the order of $1.8 billion per year, so if they came close to paying $300 million a year, then Yahoo! has to presume they are going to get at least a few percentage points of search marketshare lift for this to pay for itself.
It also makes sense that Yahoo! would be a more natural partner fit for Mozilla than Bing would. If Mozilla partnered with Bing they would risk developer blowback from pent up rage about anti-competitive Internet Explorer business practices from 10 or 15 years ago.
It is also worth mentioning our recent post about how Yahoo! boosts search RPM by doing about a half dozen different tricks to preference paid search results while blending in the organic results.
Yahoo Ads
Yahoo Organic Results
Placement
top of the page
below the ads
Background color
none / totally blended
none
Ad label
small gray text to right of advertiser URL
n/a
Sitelinks
often 5 or 6
usually none, unless branded query
Extensions
star ratings, etc.
typically none
Keyword bolding
on for title, description, URL & sitelinks
off
Underlines
ad title & sitelinks, URL on scroll over
off
Click target
entire background of ad area is clickable
only the listing title is clickable
Though the revenue juicing stuff from above wasn’t present in the screenshot Mozilla shared about Yahoo!’s new clean search layout they will offer Firefox users.
It shows red ad labels to the left of the ads and bolding on both the ads & organics.
At Yahoo, we believe deeply in search – it’s an area of investment and opportunity for us. It’s also a key growth area for us – we’ve now seen 11 consecutive quarters of growth in our search revenue on an ex-TAC basis. This partnership helps to expand our reach in search and gives us an opportunity to work even more closely with Mozilla to find ways to innovate in search, communications, and digital content. I’m also excited about the long-term framework we developed with Mozilla for future product integrations and expansion into international markets.
Our teams worked closely with Mozilla to build a clean, modern, and immersive search experience that will launch first to Firefox’s U.S. users in December and then to all Yahoo users in early 2015.
Even if Microsoft is only getting a slice of the revenues, this makes the Bing organic & ad ecosystem stronger while hurting Google. (Unless of course this is a step 1 before Marissa finds a way to nix the Bing deal and partner back up with Google on search). Yahoo! already has a partnership to run Google contextual ads. A potential Yahoo! Google search partnership was blocked back in 2008. Yahoo! also syndicates Bing search ads in a contextual format to other sites through Media.net and has their Gemini Stream Ads product which powers some of their search ads on mobile devices and on content sites is a native ad alternative to Outbrain and Taboola. When they syndicate the native ads to other sites, the ads are called Yahoo! Recommends.
Greg Sterling worries this might be a revenue risk for Firefox: “there may be some monetary risk for Firefox in leaving Google.” Missing from that perspective:
The good thing about all the Google defections is the more networks there are the more opportunities there are to find one which works well / is a good fit for whatever you are selling, particularly as Google adds various force purchased junk to their ad network – be it mobile “Enhanced” campaigns or destroying exact match keyword targeting.
I am uncertain to what degree they are testing search results from Google, but on some web browsers I am seeing Yahoo! organics and ads powered by Bing & in other browsers I am seeing Yahoo! organics and ads powered by Google. Here are a couple screenshots.
Bing Version
Google Version
Comparing The SERPs
Notable differences between the versions:
search provider
Bing
Google
top ad color
purple
blue
top ad favicon
yes
no
clickable ad area
all
headline
ad label
right of each ad near URL
once in gray above all ads
ad URL redirect
r.msn.com
google.com
ad units above organics
5
4
ad sitelinks
many
fewer
ad star rating color
blue
yellow
Yahoo! verticals like Tumblr & Answers
mixed into organic results
not mixed in
footer “powered by Bing” message
shown
missing
When the Google ads run on the Yahoo! SERPs for many keywords I am seeing many of the search arbitrage players in the top ads. Typically these ads are more commonly relegated to Google.com’s right rail ad positions.
The Google Yahoo! Search Backstory
Back in 2008 when Yahoo! was fighting to not get acquired they signed an ad agreement with Google, but it was blocked by the DOJ due to antitrust concerns. Unless Google loses Apple as a search partner, they are arguably more dominant today in general web search than they were back in 2008. Some have argued apps drastically change the way people search, but Google has went to great lengths to depreciate the roll of apps & suck people back into their search ecosystem with features baked into Google Now on tap & in-app keyword highlighting that can push a user from an app into a Google search result.
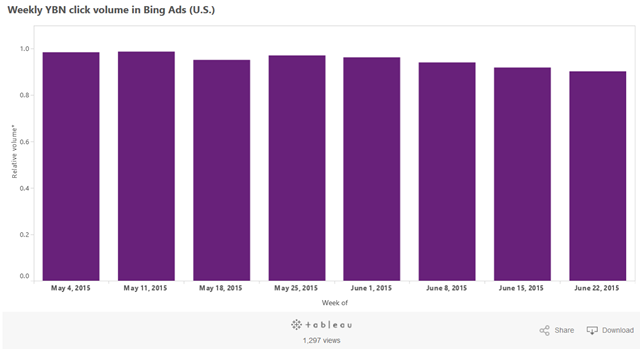
A little over a year ago Yahoo! launched Gemini to begin rebuilding their own search ad network, starting with mobile. In their Q1 report, RKG stated “Among advertisers adopting Gemini, 36% of combined Bing and Yahoo mobile traffic was served by Yahoo in March 2015.”
When Yahoo! recently renewed their search deal with Microsoft, Yahoo! was once again allowed to sell their own desktop search ads & they are only required to give 51% of the search volume to Bing. There has been significant speculation as to what Yahoo! would do with the carve out. Would they build their own search technology? Would they outsource to Google to increase search ad revenues? It appears they are doing a bit of everything – some Bing ads, some Yahoo! ads, some Google ads.
Bing reports the relative share of Yahoo! search ad volume they deliver on a rolling basis: “data covers all device-types. The relative volume (y-axis) is an index based on average traffic in April, therefore it is possible for the volume to go above 1.0. The chart is updated on a weekly basis.”
If Yahoo! gives Google significant share it could create issues where users who switch between the different algorithms might get frustrated by the results being significantly different. Or if users don’t care it could prove general web search is so highly commoditized the average searcher is totally unaware of the changes. The latter is more likely, given most searchers can’t even distinguish between search ads and organic search results.
A cynic might question how much actual choice there is if on many searches the logo is different but the underlying ads & organic results are powered by Google, and an ex-Google executive runs Yahoo!.
“Any customer can have a car painted any colour that he wants so long as it is black.” – Henry Ford
http://www.onlineparentdeals.com How to make money Online with YouTube Part 1 http://youtu.be/kN0Aq_hWfIE how to make money Online with YouTube Part 2 URL ht…
One wonders how Yahoo Search revenues keep growing even as Yahoo’s search marketshare is in perpetual decline.
Then one looks at a Yahoo SERP and quickly understands what is going on.
Here’s a Yahoo SERP test I saw this morning
I sometimes play a “spot the difference” game with my wife. She’s far better at it than I am, but even to a blind man like me there are about a half-dozen enhancements to the above search results to juice ad clicks. Some of them are hard to notice unless you interact with the page, but here’s a few of them I noticed…
Yahoo Ads
Yahoo Organic Results
Placement
top of the page
below the ads
Background color
none / totally blended
none
Ad label
small gray text to right of advertiser URL
n/a
Sitelinks
often 5 or 6
usually none, unless branded query
Extensions
star ratings, etc.
typically none
Keyword bolding
on for title, description, URL & sitelinks
off
Underlines
ad title & sitelinks, URL on scroll over
off
Click target
entire background of ad area is clickable
only the listing title is clickable
What is even more telling about how Yahoo disadvantages the organic result set is when one of their verticals is included in the result set they include the bolding which is missing from other listings. Some of their organic result sets are crazy with the amount of vertical inclusions. On a single result set I’ve seen separate “organic” inclusions for
Yahoo News
stories on Yahoo
Yahoo Answers
They also have other inclusions like shopping search, local search, image search, Yahoo screen, video search, Tumblr and more.
Here are a couple examples.
This one includes an extended paid affiliate listing with SeatGeek & Tumblr.
This one includes rich formatting on Instructibles and Yahoo Answers.
This one includes product search blended into the middle of the organic result set.
From time to time, you may get clients that want share counts to be displayed on their site. There are indeed SAAS (software as a service) services out there that do this for you, but what if a third party isn’t possible? Since Twitter dropped their JSON endpoint for share counts, a lot of people are looking to these services, and most are commercial, offer a lot of bloat, and just do MORE than what you want. Instead, learn how to use the Twitter REST API to your advantage when counting your tweets.
Getting Started
To get going, you’re going to need two things at minimum. First and foremost, I’m not going to go into detail about how OAuth works, so for that we’ll use Abraham’s Oauth Library. If you don’t use composer, click the Manual Installation tab, and download it from his GitHub. Secondly, you’ll need a Twitter app. For this DIY, we’re going to be bending the REST API to do our bidding, and for that, you need an app. If you want to wing it and think you’ll be okay without instructions, here’s a handy link to get you there. If you’re not entirely sure how to register an app with Twitter, follow this blog post on iag.me which shows you how to register a Twitter app.
Once you make your app, go to ‘Keys and Access Tokens’ and note the following (you’ll need them in the code coming up):
Consumer Key
Consumer Secret
Access Token
Access Token Secret
On to the Code!!!
For the purposes of this tutorial, we’re going to use a simple singleton class. We know that for a definite we need a template tag to display the count. One other thing to keep in mind is Twitter’s rate limit; each API call has its own limits, so for this we’re going to use the GET search/tweets endpoint, which has a rate limit of 180 calls per fifteen minutes. Due to this rate limit, you want to make sure to cache the resulting count; for this I’m using transients, however, if you have a persistent cache like WP Engine, you may want to use wp_cache_get/set functions instead. So here’s our scaffolding:
<?php
class Twitter_Counts {
/**
* @var Twitter_Counts null
*/
public static $instance = null;
private function __construct() {
// Fancy stuff.
}
public static function get_instance() {
if ( is_null( self::$instance ) ) {
self::$instance = new self;
}
return self::$instance;
}
public function tweet_count( $post_id ) {
}
}
function Twitter_Counts() {
return Twitter_Counts::get_instance();
}
function display_tweet_counts( $post_id = 0 ) {
if ( empty( $post_id ) ) {
$post_id = get_the_ID();
}
$cache_key = md5( 'twitter_counts_' . $post_id );
$count = get_transient( $cache_key );
if ( false == $count ) {
$tc = Twitter_Counts();
// ... do stuff
}
return $count;
}
Now that the scaffolding is setup, we need to start talking to Twitter with the OAuth library you downloaded. So setting it up is insanely easy (which is why I love this library):
require_once 'twitteroauth/autoload.php';
use AbrahamTwitterOAuthTwitterOAuth;
class Twitter_Counts {
/**
* @var Twitter_Counts null
*/
public static $instance = null;
private $consumer_key = '';
private $consumer_secret = '';
private $access_token = '';
private $access_secret = '';
private function __construct() {
// Fancy stuff.
}
public static function get_instance() {
if ( is_null( self::$instance ) ) {
self::$instance = new self;
}
return self::$instance;
}
public function tweet_count( $post_id ) {
$oauth = new TwitterOAuth( $this->consumer_key, $this->consumer_secret, $this->access_token, $this->access_secret );
}
}
If you are using Composer, you can ignore the first two lines. For me, I downloaded the library into a twitteroauth folder. Below that, you’ll see that there are new private variables. Since these are basically like passwords, it’s best if they’re inaccessible to anyone but the main class (although of course your requirements may be different and you’ll have to accommodate for that accordingly). Here is where those app values you copied from Twitter will come in handy; you’ll need to fill in these variables.
Line 29 is where the values are used. This literally does the OAuth handshake for you, and now all we have to do is make the request we want and process the results.
Getting the Data
Using the OAuth library makes it simple to do get requests. If you want to know all the parameters for the endpoint we’re using, you’ll need to consult the official search/tweets endpoint documentation. For now, we only need to worry about q, count, and include_entities.
Since we’re using the search endpoint, we need to search something unique to the page we’re looking at, or wanting counts for, that would be included in the tweet. Can’t get much more unique than the URL, right? We also want to return as many results as possible, this will help us in possibly going around the rate limit (unless you have a page with a million likes). For this, we set count to 100. Finally, we want to make sure to include Entities, since from what I can tell, those include the original URL prior to it being converted to the t.co shortener.
Looking at the results on the official documentation you’ll see that you get back a JSON object. A quite large one in fact, but don’t let that scare you, in the end, it’s all data, and we tell it what to do! So what do we do? Well, since the JSON data is keyed, you’ll see the main key we’re concerned with, statuses. Lastly we should also check if the property is available after the transformation by using an isset check.
Having as many checks as necessary prevents your debug log filling up. Alternatively, if you want to log these errors, you can do so in a much nicer manner. For that, you should read my other post on Debugging WordPress Tips and Snippets.
Now that we got those checks out of the way, it’s a simple as running count() over the statuses. The code goes like so:
Now we have to wrap up–this is the simple part! Here we need to update our display_tweet_counts() template tag to actually use our tweet counting method. Since our count method can return a boolean value (true/false) we want to check for that and set the count to zero if there was a problem. Otherwise, we want to use the actual value.
So here’s the full code:
require_once 'twitteroauth/autoload.php';
use AbrahamTwitterOAuthTwitterOAuth;
class Twitter_Counts {
/**
* @var Twitter_Counts null
*/
public static $instance = null;
// You'll need to fill these in with your own data.
private $consumer_key = '';
private $consumer_secret = '';
private $access_token = '';
private $access_secret = '';
private function __construct() {
// Fancy stuff.
}
public static function get_instance() {
if ( is_null( self::$instance ) ) {
self::$instance = new self;
}
return self::$instance;
}
public function tweet_count( $post_id ) {
$defaults = array(
'q' => get_permalink( $post_id ),
'count' => 100,
'include_entities' => true,
);
$oauth = new TwitterOAuth( $this->consumer_key, $this->consumer_secret, $this->access_token, $this->access_secret );
$statuses = $oauth->get( 'search/tweets', $defaults );
if ( ! $statuses ) {
return false;
}
if ( ! isset( $statuses->statuses ) ) {
return false;
}
return count( $statuses->statuses );
}
}
function Twitter_Counts() {
return Twitter_Counts::get_instance();
}
function display_tweet_counts( $post_id = 0 ) {
if ( empty( $post_id ) ) {
$post_id = get_the_ID();
}
$cache_key = md5( 'twitter_counts_' . $post_id );
$count = get_transient( $cache_key );
if ( false == $count ) {
$tc = Twitter_Counts();
$result = $tc->tweet_count( $post_id );
$count = false == $result ? 0 : $result;
set_transient( $cache_key, $count, 1 * HOUR_IN_SECONDS );
}
return $count;
}
What about pages with 100+ shares?
That comes in part two, so stay tuned! In part two, we’re going to get into recursion, and how to walk over the results page-by-page. Keep an eye out for the second installment, and let me know if you have any questions!
http://www.onlineparentdeals.com How to make money Online with YouTube Part 1 http://youtu.be/kN0Aq_hWfIE how to make money Online with YouTube Part 2 URL ht…
Smashing Magazine is known for lengthy, comprehensive articles. But what about something different for a change? What about shorter, concise pieces with useful tips that you could easily read over a short coffee break? As an experiment, this is one of the shorter “Quick Tips”-kind-of articles — shorter posts prepared and edited by our editorial team. What do you think? Let us know in the comments! —Ed.
The Internet is the foundation of our craft. But what do we actually know about its underlying technology? How do DNS, networks and HTTPS work? What happens in the browser when we type a URL in the address bar?
A 301 Redirect is a mechanism to change the URL automatically from one to the other when the first one is accessed. It’s a common mechanism understood throughout the internet, used mostly for SEO purposes....
Foundation for Apps is a new single-page app1 framework from Zurb that is closely related to Foundation 5 (also known as Foundation for Sites, a widely used front-end framework). It’s built around AngularJS and a flexbox grid framework. It’s intended to make creating a web app very quick and simple, enabling us to quickly start writing the code that’s unique to our application, rather than boilerplate.
Because Foundation for Apps was only released at the end of 2014, it hasn’t yet seen widespread usage, so there are few good sources of information on using the framework. This article is meant to be a comprehensive guide to building a functional web app with Foundation for Apps from start to finish. The techniques detailed here are fundamental to building practically any kind of app for any client, and this tutorial also serves as a strong introduction to the wider world of AngularJS and single-page apps.
In light of the new film being released later this year, we’ll be building a Star Wars knowledge base. It will be a responsive web application, using a RESTful2 API, caching and many of the features that Foundation for Apps3 and AngularJS offer.
Take a quick squiz through the official documentation7, which explains the styling aspects well but doesn’t go into detail about application functionality. Also, keep AngularJS’ excellent documentation8 handy, bearing in mind that Foundation for Apps includes some services that aren’t standard and that some AngularJS functions might not work out of the box. Keep in mind also that, natively, AngularJS and Foundation for Apps aren’t particularly well suited to apps that need significant SEO, since most content is loaded via AJAX.
Our app will get its data from the handy Star Wars API found at SWAPI9. Take a look through SWAPI’s documentation3310 to get a feel for the data served and its structure. Our application will be based on that structure for simplicity.
First, let’s install Foundation for Apps and create our project. Make sure that Ruby11 (already on OS X by default) and Node.js12 are installed, and then follow the four-step process detailed in the documentation13. It’s pretty straightforward, even if you haven’t used the command line before. Once you’ve finished the process, your browser should display the default home page of your application at http://localhost:8080/#!/.
Let’s get acquainted with the project’s files and folders.
The only file in our app’s base directory that we need to pay attention to is gulpfile.js, which gives instructions to the Gulp process16 that we’ve already used to start the server for our app. Gulp is a build system17, and it’s very similar to Grunt18. Later on, if we want to add some AngularJS modules or plugins, we’ll need to update this Gulp file with references to the JavaScript or CSS files for those modules or plugins.
The client folder is where we’ll find all of the other files we’re concerned with:
clients/assets/js/app.js is where our controller, directives and custom filters will be for this application;
All of our app’s SCSS can be found in clients/assets/scss, naturally;
clients/index.html is the base template for our application;
clients/templates/ is where we’ll find the template for all of our pages, most of which haven’t been created yet.
Build The Template And Home Screen
Let’s start building! First, modify the index.html page, which doesn’t start out very well optimized for a real application. We’ll add an off-canvas menu for small screens, a button to toggle its opening, and a nice fade effect using classes from Foundation for Apps’ “Motion UI.” You can copy the code from the index.html file in our repository19.
We’ll add some SCSS variables to our _settings.scss file to set our colors, fonts and breakpoints:
Now we’re cooking with gas. In our templates folder, create a template file for our first subpage: films.html. Paste this snippet at the top:
---
name: films
url: /films/:id?p=
controller: FilmsCtrl
---
This tells our app three things:
In links to this page, we’ll refer to the page as films
The URL will have two possible parameters: id (the ID of the film, according to our data) and p (the page number in the listing of all films).
We’ll be using our own custom AngularJS controller, called FilmsCtrl, instead of the default blank one that Foundation for Apps creates automatically.
Because we’re using our own controller, let’s go ahead and create one in app.js. Look through the controller below, which we’ll be using for both our list of films and our single-film pages. You can see that this controller keeps track of URL parameters, figures out what page of results we’re on, gets the necessary data (either a list of films or details of an individual film, depending on the URL’s parameters) from our external API, and returns it to our view using the $scope variable. Add it to app.js after the angular.module declaration closes:
controller('FilmsCtrl',
["$scope", "$state", "$http",function($scope, $state, $http){
// Grab URL parameters - this is unique to FFA, not standard for
// AngularJS. Ensure $state is included in your dependencies list
// in the controller definition above.
$scope.id = ($state.params.id || '');
$scope.page = ($state.params.p || 1);
// If we're on the first page or page is set to default
if ($scope.page == 1) {
if ($scope.id != '') {
// We've got a URL parameter, so let's get the single entity's
// data from our data source
$http.get("http://swapi.co/api/"+'films'+"/"+$scope.id,
{cache: true })
.success(function(data) {
// If the request succeeds, assign our data to the 'film'
// variable, passed to our page through $scope
$scope['film'] = data;
})
} else {
// There is no ID, so we'll show a list of all films.
// We're on page 1, so the next page is 2.
$http.get("http://swapi.co/api/"+'films'+"/", { cache: true })
.success(function(data) {
$scope['films'] = data;
if (data['next']) $scope.nextPage = 2;
});
}
} else {
// Once again, there is no ID, so we'll show a list of all films.
// If there's a next page, let's add it. Otherwise just add the
// previous page button.
$http.get("http://swapi.co/api/"+'films'+"/?page="+$scope.page,
{ cache: true }).success(function(data) {
$scope['films'] = data;
if (data['next']) $scope.nextPage = 1*$scope.page + 1;
});
$scope.prevPage = 1*$scope.page - 1;
}
return $scope;
}]) // Ensure you don't end in a semicolon, because more
// actions are to follow.
After saving app.js, you may need to restart your server using the terminal (Control + C to cancel the operation and then foundation-apps watch again) to ensure that your app includes the new template file you’ve created along with the new controller.
And just like that, we have a fully functional controller that gets data from an external RESTful API source, caches the result in the browser’s session and returns the data to our view!
Open up films.html again, and let’s start building the view of the data that we can now access. Begin by adding the base view, which will show a list of films. We can access all properties that we’ve added to our $scope variable, without prefixing them with $scope, such as (in this case) films, prevPage and nextPage. Add the following below the template’s existing content:
Bodacious! We’ve got a list of film names as well as pagination if there are multiple pages of data. But that’s not especially useful yet — let’s turn the film’s name into a link to that film’s page in our app.
We plan to use the film’s ID as the id parameter in our URL, and we have access to the film’s url attribute, which happens to have the film’s ID as its last parameter before the final slash. But how do we grab only the ID out of the URL that we have access to? AngularJS makes it easy with custom filters23. Let’s wrap our {{film.title}} in a link, add a ui-sref attribute (which sets up an internal link) and use our film.url data with a custom filter applied to it:
Well, now our page is broken because our app doesn’t know what the lastdir and capitalize filters are. We need to define those filters in our app.js file, placed just after our controller:
.filter('capitalize', function() {
// Send the results of this manipulating function
// back to the view.
return function (input) {
// If input exists, replace the first letter of
// each word with its capital equivalent.
return (!!input) ? input.replace(/([^W_]+[^s-]*) */g,
function(txt){return txt.charAt(0).toUpperCase() +
txt.substr(1)}) : '';
}
})
.filter('lastdir', function () {
// Send the results of this manipulating function
// back to the view.
return function (input) {
// Simple JavaScript to split and slice like a fine chef.
return (!!input) ? input.split('/').slice(-2, -1)[0] : '';
}
})
Bingo! We now have a list of films, each of which links to its respective film page.
24 Our linked list of films: Not sure why we bothered with the prequels. (View large version25)
However, that link just takes us to an empty page at the moment, because films.html hasn’t been set up to show a specific film, rather than the whole list. That’s our next step.
Displaying Details Of A Single Film
We’ve already set up all of the data we need for the single-film page in our FilmsCtrl controller in the $scope.film variable (which is the same as $scope['film']). So, let’s reuse films.html and add another section that’s visible only when the singular film variable is set. We’ll set each key-value pair to use <dt> and <dd> within a <dl> because we’re not unsemantic swine26. Remember also that some of film’s fields, such as characters, have multiple values in an array, so we’ll need to use ng-repeat for those to display each value. To link each character to its character page, we’ll use the same method that we used in the listing of films: Using our lastdir filter, we link to each character’s people page by his/her/its ID.
We need to replace that text with the character’s name, but we don’t have that critical piece of data. Perhaps we could look up that URL using the same method we used to get our film in the first place — then, the data we receive from the call would contain the character’s name. Let’s open up app.js again and add a directive29, which we’ll call getProp.
.directive("getProp", ['$http', '$filter', function($http, $filter) {
return {
// All we're going to display is the scope's property variable.
template: "{{property}}",
scope: {
// Rather than hard-coding 'name' as in 'person.name', we may need
// to access 'title' in some instances, so we use a variable (prop) instead.
prop: "=",
// This is the swapi.co URL that we pass to the directive.
url: "="
},
link: function(scope, element, attrs) {
// Make our 'capitalize' filter usable here
var capitalize = $filter('capitalize');
// Make an http request for the 'url' variable passed to this directive
$http.get(scope.url, { cache: true }).then(function(result) {
// Get the 'prop' property of our returned data so we can use it in the template.
scope.property = capitalize(result.data[scope.prop]);
}, function(err) {
// If there's an error, just return 'Unknown'.
scope.property = "Unknown";
});
}
}
}])
getProp returns a single property from the data resulting from our $http.get call, and we can specify which property we want. To use this directive, we need to add it to the area within our ng-repeat, like so:
Nice. We now have each character’s name instead of just a wild URL, and each links to its respective page. Now our single film view will be complete once the rest of the data fields are added to the view (see films.html in the repository30 for the rest).
Looking through SWAPI’s documentation3310 and our plans for the rest of the application, we clearly see that our controllers for all other pages will be extremely similar to this one, varying only in the category of data we’re getting.
With that in mind, let’s move the code inside our films controller to its own function, called genericController, placed just before the last closing brackets of app.js. We also need to replace every instance of the string 'films' with the variable multiple (five instances) and 'film' with single (one instance), because they represent the multiple and singular forms of the entity of each page. This allows us to create very DRY34, reusable code that’s also easier to read and understand.
Now we can add a call in our FilmsCtrl controller to our new genericController function with our two variables (multiple and single versions of our data), passed as parameters:
Excellent! We have a reusable controller that grabs the data we need for any given page and puts it in a usable format! We can now easily create our other pages’ controllers just after FilmsCtrl in the same way:
Go ahead and create the template HTML files for planets, species, people, starships and vehicles in the same way we created films.html but referencing the fields in SWAPI’s docs35 for each respective category of data.
Voila! All of our pages now show the correct data and interlink with one another!
Our application is complete! Our demo (linked to below) is hosted by Aerobatic38, which exclusively targets front-end web applications. You’ll see in our repository that we’ve added some domain-specific options to take advantage of Aerobatic’s API gateway, which sets up a proxy that caches the API’s data on the server once we request it. Without caching, the application would be both latency-limited and request-limited (SWAPI allows only so many requests per domain, as do most other APIs), and because our data isn’t likely to change often, that server caching makes everything very speedy after the first load. Because we’ve limited our onload requests and images, even the first load will be acceptable on a slow connection, and on each page load, the header menu will stay on the page, making the application feel fast.
In the demo and repository, you can see that we’ve also added another API call on the details pages, which grabs an image URL for each entity from a Google custom search that we set up to trawl Wookieepedia39 and StarWars.com40. So, we’ve now got dynamic, highly relevant images showing up on each detail page.
Take a look at the demo below, or look through the source code for some hidden goodies and more Foundation-specific tricks, or download the repository and build on it locally with your own improvements.
Creating A Complete Web App In Foundation For Apps http://www.smashingmagazine.com/2015/04/28/creating-web-app-in-foundation-for-apps/ http://www.smashingmagazine.com/feed/?# Smashing Magazine For Professional Web Designers and Developers
This is a guest contribution by Felipe Kurpiel, an internet marketer
I came across this topic by accident. One day I was monitoring my analytics data I noticed a big drop on my traffic stats and I didn’t understand why.
Actually, I had a hint because I was starting to interlink my posts. That gave me a clue that the problem was internal which I thought was a good thing. But that is not enough because then I had to analyze what Google is focusing on now.
If you have been involved with SEO at all you know that duplicate content is a bad thing. But how can you identify the duplicate content on your site?
Ok, let’s get started with that.
Identifying Internal Duplicate Content!
That is a little advanced because we are about the crawl our website the way Google does. That is the best way to analyze the source of any problems.
To do that I like to use a Free Tool called Screaming Frog SEO Spider. If you never used this tool it can be a little complicated but don’t let that scares you.
You just have to follow some steps. Actually you can analyze a lot of factors using this tool but for our example, we are just considering duplicate content.
First Step: Add your URL website into the software and let it run.
It can take a while depending on how big your website is, but after that we are ready to filter what we are looking for.
Second: Go to the Page Titles tab and then filter by Duplicate
If you are lucky you will not have any result showing when you choose this filter. But unfortunately that was not my case and I saw dozens of results which were the proof that my website had internal duplicate content.
Third Step: It’s time to analyze what is generating the problem
You can do this on Screaming Frog or you can export the file to Microsoft Excel (or similar) in order to deeply analyze what you have to do to solve the issue.
In my case, the duplicate content was being generated by comments. Weird, isn’t?
That is what I thought and I also noticed that the pages with comments were being flagged by Google because they disappeared from search results.
When that happens, you have no turning back but fix the source of the problem.
Understanding Comments
Every comment on my website was generating a variable named “?replytocom”.
You don’t need to understand exactly what this variable does but put it simple; it is like each comment you have on your posts has the ability to create a copy of this particular post in your site. It can be considered as a pagination problem. And that is terrible because when Google crawl your website it can see that your site has the same content being repeated over and over again.
Do you think you are going to rank with that blog post? Not a change!
How to solve this problem
More important than to identify this issue is to create a clear solution to get rid of this pagination issue.
In order to deal with this variable there are two solutions. The first is really simple but not so effective and the second can be seen as complicated but it’s really the ultimate solution.
But let’s cover the easy solution first.
I run my blog on WordPress and one of the few essential plugins I use for SEO is WP SEO by Yoast. If you are using this plugin you just have to go to the plugin dashboard and then click on Permalinks. Once you do that just check the box to “Remove ?replytocom variables”.
This is really simple but sometimes you won’t get the results you are expecting, however, if you are having this kind of problem with comments you MUST check this option.
Second Option
After that you can run your website URL using Screaming Frog to see if the problem was solved. Unfortunately this can take a while but if after one day or two you are still noticing problems for duplicated content you have to try the second option.
Then under Configuration we must go to URL Parameters.
We will see a list of parameters being crawled by Google in addition, here we have the chance to tell Google what to do when a parameter in particular is affecting our website. That is really cool.
For this replytocom problem I just have to click Edit and use the following settings.
Click Save and you solved the problem!
Now if you tried the first option using the plugin, then you used Webmaster Tools to tell Google what to do with this parameter and after a few days you still see duplicate content, there is one more thing you can try!
Now I am talking about Robots.txt!
Don’t worry if you don’t have this file on your website, because you just have to create a txt file and upload it on the root of your domain. Nothing that complicated!
Once you have created this file you just have to add a command line in the file.
If your Robots.txt is blank, just add these commands there:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: *?replytocom
If you already had this file, just add the final line: “Disallow: *?replytocom”
It will for sure take care of everything!
Final Thoughts and Monitoring
The best way to avoid this or similar problems is monitoring your data. So here are my three tips to keep your website Google friendly.
When working On-Page be careful with the settings you are using on Yoast WordPress SEO plugin. Don’t forget to review Titles & Metas tab and check the “no index, follow” option for every little thing that can be considered as duplicate content.
An example is the “Other” tab where you MUST check this “no index” option so your Author Archives will not be seen as duplicate content when Google crawls your site. Remember, you have to make your website good for users and for search engines.
At least twice a week, analyze your traffic on Google Analytics. Go to Traffic Sources tab then Search Engine Optimization and keep an eye on Impressions.
You should also use an additional tool to track your keywords rankings so you can see if your search engine positions remain intact or if some of them are facing some drops. When that happens you will know it’s time to take some action.
Every two weeks, use Screaming Frog to crawl your website. This can be really important to check if the changes you made on-site already had the impact you were expecting.
When it comes to duplicate content the most important tabs to monitor on Screaming Frog are Page Title and Meta Description. However, in order to have a website that can be considered Google friendly it’s vital to analyze the Response Codes as well and eliminate every Client Error (4xx) and Server Error (5xx) you identify when crawling it.
Felipe Kurpiel is an internet marketer passionate about SEO and affiliate marketing. On his blog there are great insights about how to rank your website, link building strategies and YouTube marketing.
How To Stop Your WordPress Blog Getting Penalized For Duplicate Content http://www.problogger.net/archives/2013/08/14/how-to-stop-your-wordpress-blog-getting-penalized-for-duplicate-content/ http://www.problogger.net/search/affiliate+marketing/feed/rss2/ @ProBlogger» Search Results » affiliate+marketing Blog Tips to Help You Make Money Blogging – ProBlogger http://www.problogger.net/wp-content/plugins/podpress/images/powered_by_podpress_large.jpg