What’s new with Woo: July 2024

What’s happening with WooCommerce in July 2024? Cart and Checkout upgrades, Buy Now, Pay Later, and more!

Tips, Expertise, Articles and Advice from the Pro's for Your Website or Blog to Succeed
In the fast-paced world of digital marketing, having an exceptional website is crucial for your agency’s success. It’s more than just a digital brochure—it’s your brand’s online personality, a client magnet, and a showcase of your expertise. Elementor is a game-changer in this arena, providing tools to craft visually stunning sites effortlessly. This post will dive into why free Elementor templates are worth considering, how to select the best one for your agency, and tips to make your site truly stand out.
Budget-friendly : Free marketing agency Elementor templates are a savvy choice for keeping costs down while still achieving a professional-looking website. Instead of investing heavily in custom designs or pricey developers, you can leverage these high-quality, no-cost templates to build a site that looks great and functions well.
Efficient : Time is of the essence, and free Elementor website templates for marketing streamline the development process. With these templates, you can quickly set up your site and redirect your energy towards creating compelling content and engaging with clients.
Professional quality : The “free” label doesn’t mean you have to sacrifice quality. Many of these best free Elementor templates for marketing agencies are crafted by experienced designers and offer sleek, modern designs. They come with responsive layouts and eye-catching features that help your site make a strong impression.
Match your niche : Consider the specific focus of your agency when choosing a template. Whether you specialize in digital marketing, creative design, or consulting, select a template that reflects your industry. This ensures that your site resonates with your target audience.
Feature check : Look closely at what the template offers. Does it include customizable sections, responsive design, and the right integrations? Opt for marketing agency website templates Elementor that align with your needs—whether it’s showcasing a portfolio, displaying client testimonials, or outlining service offerings.
Brand alignment : A template is a starting point. Customize it to reflect your brand’s personality. Adjust colors, fonts, and layouts so your site becomes a true representation of your agency’s identity.
Customization options : Elementor provides extensive customization features to refine your template. Use the drag-and-drop editor to rearrange elements and personalize the design. This way, your site won’t just look good—it’ll look distinctly yours.
Content matters : After setting up your template, focus on adding engaging content. Make sure your text, images, and videos are relevant and compelling. Excellent content helps captivate visitors and convert them into clients.
SEO savvy : Don’t forget about SEO. Elementor offers built-in features and plugins to help you optimize your site’s meta tags, headings, and images. A well-optimized site improves your search engine ranking and attracts more traffic.
To wrap up, free digital marketing agency Elementor templates offer a cost-effective, efficient, and high-quality solution for creating a standout website. By choosing the right template, customizing it to match your brand, and utilizing Elementor’s powerful tools, you can build a site that truly shines. Ready to enhance your agency’s online presence? Explore these templates today, and for more insights and updates, subscribe to our newsletter or visit our website.




















The post The Ultimate Collection of Elementor Templates for Marketing Agencies appeared first on CSS Author.
I was at a tech conference recently – one built by (and for) networking professionals – chatting with another attendee about the usual mix of news, tech challenges, and hobbies when the conversation took a sudden and sobering turn:
“I guess I have a lot more time for side quests these days. I got laid off a couple of months back and can’t seem to land even a solid conversation, let alone a job offer. I thought it would be easier than this.”

In my experience of building and supporting UX teams, most of them are significantly under-resourced. In fact, the term "team" can often be a stretch, with many user experience professionals finding themselves alone in their roles.
Typically, there are way more projects that impact the user experience than the team can realistically work on. Consequently, most UX teams are in a constant state of firefighting and achieve relatively little in improving the overall experience.
We can complain about being under-resourced as much as we want, but the truth is that our teams are unlikely to grow to a size where we have sufficient staff to address every detail of the experience. Therefore, in this post, I want to step back and reconsider the role of user experience professionals and how UX teams can best improve the user experience of an organization.
What Is The Role Of A UX Professional?There is a danger that as UX professionals, we focus too much on the tools of our trade rather than the desired outcome.
In other words, we tend to think that our role involves activities such as:
But these are merely the means to an end, not the end goal itself. These activities are also time-consuming and resource-intensive, potentially monopolizing the attention of a small UX team.
Our true role is to improve the user experience as they interact with our organization's digital channels.
The ultimate goal for a UX team should be to tangibly enhance the customer experience, rather than solely focusing on executing design artifacts.
This reframing of our role opens up new possibilities for how we can best serve our organizations and their customers. Instead of solely focusing on the tactical activities of UX, we must proactively identify the most impactful opportunities to enhance the overall customer experience.
Changing How We Approach Our RoleIf our goal is to elevate the customer experience, rather than solely executing UX activities, we need to change how we approach our role, especially in under-resourced teams.
To maximize our impact, we must shift from a tactical, project-based mindset to a more strategic, leadership-oriented one.
We need to become experience evangelists who can influence the broader organization and inspire others to prioritize and champion user experience improvements across the business.
As I help shape UX teams in organizations, I achieve this by focusing on four critical areas:
Let’s explore these in turn.
It is important for any UX team to demonstrate its value to the organization. One way to achieve this is by creating a set of tangible resources that can be utilized by others throughout the organization.
Therefore, when creating a new UX team, I initially focus on establishing a core set of resources that provide value and leave an impressive impression.
Some of the resources I typically focus on producing include:

These resources need to be viewed as living services that your UX team supports and refines over time. Note as well that these resources include educational elements. The importance of education and training cannot be overstated.
By providing training and educational resources, your UX team can empower and upskill the broader organization, enabling them to better prioritize and champion user experience improvements. This approach effectively extends the team’s reach beyond its limited internal headcount, seeking to turn everybody into user experience practitioners.
This training provision should include a blend of 'live' learning and self-learning materials, with a greater focus on the latter since it can be created once and updated periodically.
Most of the self-learning content will be integrated into the playbook and will either be custom-created by your UX team (when specific to your organization) or purchased (when more generic).

In addition to this self-learning content, the team can also offer longer workshops, lunchtime inspirational presentations, and possibly even in-house conferences.
Of course, the devil can be in the details when it comes to the user experience, so colleagues across the organization will also need individual support.
Although your UX team may not have the capacity to work directly on every customer experience initiative, you can provide consultative services to guide and support other teams. This strategic approach enables your UX team to have a more significant impact by empowering and upskilling the broader organization, rather than solely concentrating on executing design artifacts.
Services I tend to offer include:
But it is important that your UX team limits their involvement and resists the urge to get deeply involved in the execution of every project. Their role is to be an advisor, not an implementer.
Through the provision of these consultative services, your UX team will start identifying individuals across the organization who value user experience and recognize its importance to some degree. The ultimate goal is to transform these individuals into advocates for UX, a process that can be facilitated by establishing a UX community within your organization.
Building a UX community within the organization can amplify the impact of your UX team's efforts and create a cohesive culture focused on customer experience. This community can serve as a network of champions and advocates for user experience, helping spread awareness and best practices throughout the organization.
Begin by creating a mailing list or a Teams/Slack channel. Using these platforms, your UX team can exchange best practices, tips, and success stories. Additionally, you can interact with the community by posing questions, creating challenges, and organizing group activities.

For example, your UX team could facilitate the creation of design principles by the community, which could then be promoted organization-wide. The team could also nurture a sense of friendly competition by encouraging community members to rate their digital services against the System Usability Scale or another metric.
The goal is to keep UX advocates engaged and advocating for UX within their teams, with a continual focus on growing the group and bringing more people into the fold.
Finally, this community can be rewarded for their contributions. For example, they could have priority access to services or early access to educational programs. Anything to make them feel like they are a part of something special.
An Approach Not Without Its ChallengesI understand that many of my suggestions may seem unattainable. Undoubtedly, you are deeply immersed in day-to-day project tasks and troubleshooting. I acknowledge that it is much easier to establish this model when starting from a blank canvas. However, it is possible to transition an existing UX team from tactical project work to UX leadership.
The key to success lies in establishing a new, clear mandate for the group, rather than having it defined by past expectations. This new mandate needs to be supported by senior management, which means securing their buy-in and understanding of the broader value that user experience can provide to the organization.
I tend to approach this by suggesting that your UX team be redefined as a center of excellence (CoE). A CoE refers to a team or department that develops specialized expertise in a particular area and then disseminates that knowledge throughout the organization.
This term is familiar to management and helps shift management and colleague thinking away from viewing the team as UX implementors to a leadership role. Alongside this new definition, I also seek to establish new objectives and key performance indicators with management.
These new objectives should focus on education and empowerment, not implementation. When it comes to key performance indicators, they should revolve around the organization's understanding of UX, overall user satisfaction, and productivity metrics, rather than the success or failure of individual projects.
It is not an easy shift to make, but if you do it successfully, your UX team can evolve into a powerful force for driving customer-centric innovation throughout the organization.
CSS has a feature called Custom Properties. You know this.
html {
--brandColor: red;
}
.card {
border-color: var(--brandColor);
h2 {
color: var(--brandColor);
}
}People also — somewhat interchangeably — refer to these as CSS variables. Somehow, that doesn’t bother me, even though I tend to be a stickler about naming things. For instance, there is no such thing as a frontend developer. There are front-end developers who focus on the front end.
But here, the names feel like they make sense despite me not exactly nailing down how I like to see them being used. Like, Custom Property feels right. When I create --something, that’s used as a property in CSS but I just made up the name myself. It’s a… custom… property. And then I use it later with the var() function, which obviously stands for “variable”, because now this custom properties value has turned into a dynamic variable. So calling what is happening here a “CSS variable” seems entirely fine.
OK moving on I guess we need to talk about CSS variables for an entire issue.
Just the other week I was trying to see if there was a clean way to ask CSS what the value of cos(25deg) was. I feel like I got so close, trying both setting the value to a property that takes a unitless number and typing the variable first, but I couldn’t quite get it. There is a lesson here about never giving up, as Bramus proved by giving it a fresh college try and proving it absolutely can be done.
You totally do need to type variables sometimes, the 99% use case is allowing them to be animated which the browser can (mostly) on do if it knows the type. You could also consider it a form of “type safety” so hardcore TypeScript nerds will probably like it.
Above is about as niche of a situation as you can get.
What are CSS variables actually useful for?
I like thinking of the most common use case for things. The most common use case for grid is to put two things side by side. The most common use case for a <dialog> is an important confirm/cancel question. The most common use case for a popover is a footnote. The most common use case for SVG is a logo. For CSS variables, it’s a brand color.
Even on a fairly simple website, I’d bet there is one particular important color that you end up having to set a number of times. Using a variable for it just keeps things DRY and allows you to tweak it easily. That’s exactly the code I started this post out with. But variables are more and more powerful. Just that --brandColor is tweakable without changing it…
footer {
background: color-mix(in oklch, var(--brandColor), black 20%);
}Now if we tweak that brand color, we’re tweaking the tweaks (man).
Even wilder to me is that setting one custom property (see how effortless I can switch the term back and forth?) can have effects all over the place. This is thanks to container style queries.
Consider code like this:
@container style(--darkBackground) {
> * { color: white; }
}Now if --darkBackground is set (to any value at all) on any element, all direct children of it have white text. Support for this is pretty limited, so it’ll be a while until any of us have any strong understanding of how this will affect how we write CSS. To me, this is similar to :has() in how a change anywhere on the page can affect changes elsewhere in (I’d argue) unexpected ways. Powerful ways. Maybe useful ways. But unexpected ways. CSS used to be a pretty darn top-down language and that’s changing.
How about a feature with such limited support there… isn’t any. One of those things is the if() statement (woah), which is only useful for testing CSS variables. I’m a fan, but let’s not get all into that here. Another Lea Verou post is Proposal: CSS Variable Groups. Check it:
:root {
--color-green: {
100: oklch(95% 13% 135);
200: oklch(95% 15% 135);
/* ... */
900: oklch(25% 20% 135);
};
}This turns into variables that are used like var(--color-green-200). Such a chill way to declare a set of variables without so much repetition. It’s just for authors, but that’s fine I think. CSS variables I feel like exist mostly in a post-pre-processing era (heh), so even though we’d probably abstract this with a loop or whatever in the past, we don’t have that anymore, so need syntactical help.
Technology in the digital age has revolutionized our lives. However, this convenience comes with a growing threat: cybercrime. Malicious actors, ranging from petty thieves to sophisticated cybercriminals, operate online, seeking to exploit vulnerabilities and steal sensitive information, financial data, and even identities.
From online banking and shopping to social media and remote work, the internet has become an essential part of our daily routines. What does it mean when your online identity is turned against you? Or when you need to prove your own identity to regain control of tools you previously assumed were solely there to make your life easier?

We all know what importance colors hold in anything, whether it’s a website layout, image, video, or any other graphical element. In essence, color is a subjective experience that results from the interaction between light, the eye, and the brain. Adding colors to the website gives a new life to the whole layout and graphical elements. Nobody likes to visit web pages with white, black, and gray colors on them. Colors make the elements look more realistic and catchy to the human eye.
Not just theoretically, psychology also comes into play when we use colors on websites. It has been scientifically proven that a specific set of colors triggers particular emotions in the human brain, such as autumn colors like orange and yellow representing joy or happiness, red color to festive seasons, and blue viewed as calm and trustworthy. Besides, you must have noticed that many food companies often use red and yellow on their websites, pharmaceutical companies tend to use green on their sites, fitness companies sometimes use orange, and so on.
In the realm of digital art, Photoshop brushes are the unsung heroes that bring illustrations to life. Whether you’re sketching, painting, or adding intricate details, the right brush can be a game-changer in achieving the desired effect.
This article will delve into four essential categories of brushes that every aspiring artist should have in their arsenal:
Get ready to transform your digital creations with these indispensable tools!
When it comes to Photoshop brushes for drawing, pencil brushes are often the first choice for artists seeking to replicate the traditional pencil look. These brushes are designed to mimic the texture and feel of graphite on paper.
Ideal for everything from quick sketches to detailed illustrations, pencil brushes are essential tools for digital artists.
To elevate your digital pencil drawing, consider these practical tips:
With these techniques, you’ll be on your way to creating stunning, realistic pencil drawings in Photoshop!
Once you’ve immersed yourself in the world of pencil brushes, it’s time to explore the vibrant universe of paint brushes available in Photoshop. These brushes are designed to emulate a range of traditional painting styles.
Each type has its own unique effect, allowing artists to express their creativity in various ways.
To master painting in Photoshop, consider adopting these effective techniques :
With these skills in your toolkit, you’ll bring your digital canvas to life, one brushstroke at a time!
As we venture further into the world of Photoshop brushes for digital art, texture brushes stand out as vital tools for artists keen on enhancing their work with depth and detail. These brushes are specially crafted to introduce intricate layers that mimic the varied surfaces of traditional art.
Texture brushes allow artists to breathe life into their creations by cleverly manipulating the feel and look of surfaces.
To really make your artwork pop, try these innovative techniques with texture brushes :
By incorporating these strategies, you’ll unlock a treasure trove of unique effects that elevate your digital art to new heights!
Transitioning from texture to special effects brushes, we dive into the realm of light and shading brushes that have the power to transform your artwork instantly. These brushes are designed to mimic various sources of light, creating stunning highlights and deep shadows.
These brushes can define your art, making it come alive with emotion and depth.
To establish mood and atmosphere in your compositions, consider these effective techniques:
By mastering these techniques, you will convey powerful stories and emotions through your digital art, captivating your audience with every brushstroke!
As we’ve explored throughout this article, Photoshop brushes are indispensable tools for any digital artist. From sketching to painting, texturing and applying special effects, the right brushes elevate your artwork from ordinary to extraordinary.
Each brush type plays a vital role in enhancing your overall artistic expression.






























The post Creating Magic on Canvas: Essential Photoshop Brushes for Drawing appeared first on CSS Author.

Audio descriptions involve narrating contextual visual information in images or videos, improving user experiences, especially for those who rely on audio cues.
At the core of audio description technology are two crucial components: the description and the audio. The description involves understanding and interpreting the visual content of an image or video, which includes details such as actions, settings, expressions, and any other relevant visual information. Meanwhile, the audio component converts these descriptions into spoken words that are clear, coherent, and natural-sounding.
So, here’s something we can do: build an app that generates and announces audio descriptions. The app can integrate a pre-trained vision-language model to analyze image inputs, extract relevant information, and generate accurate descriptions. These descriptions are then converted into speech using text-to-speech technology, providing a seamless and engaging audio experience.

By the end of this tutorial, you will gain a solid grasp of the components that are used to build audio description tools. We’ll spend time discussing what VLM and TTS models are, as well as many examples of them and tooling for integrating them into your work.
When we finish, you will be ready to follow along with a second tutorial in which we level up and build a chatbot assistant that you can interact with to get more insights about your images or videos.
Vision-Language Models: An IntroductionVLMs are a form of artificial intelligence that can understand and learn from visuals and linguistic modalities.
They are trained on vast amounts of data that include images, videos, and text, allowing them to learn patterns and relationships between these modalities. In simple terms, a VLM can look at an image or video and generate a corresponding text description that accurately matches the visual content.
VLMs typically consist of three main components:
Generally speaking, the image model — also known as the vision encoder — extracts visual features from input images and maps them to the language model’s input space, creating visual tokens. The text model then processes and understands natural language by generating text embeddings. Lastly, these visual and textual representations are combined through the fusion mechanism, allowing the model to integrate visual and textual information.
VLMs bring a new level of intelligence to applications by bridging visual and linguistic understanding. Here are some of the applications where VLMs shine:
This is merely an overview of what VLMs are and the pieces that come together to generate audio descriptions. To get a clearer idea of how VLMs work, let’s look at a few real-world examples that leverage VLM processes.
VLM ExamplesBased on the use cases we covered alone, you can probably imagine that VLMs come in many forms, each with its unique strengths and applications. In this section, we will look at a few examples of VLMs that can be used for a variety of different purposes.
IDEFICS is an open-access model inspired by Deepmind’s Flamingo, designed to understand and generate text from images and text inputs. It’s similar to OpenAI’s GPT-4 model in its multimodal capabilities but is built entirely from publicly available data and models.
IDEFICS is trained on public data and models — like LLama V1 and Open Clip — and comes in two versions: the base and instructed versions, each available in 9 billion and 80 billion parameter sizes.
The model combines two pre-trained unimodal models (for vision and language) with newly added Transformer blocks that allow it to bridge the gap between understanding images and text. It’s trained on a mix of image-text pairs and multimodal web documents, enabling it to handle a wide range of visual and linguistic tasks. As a result, IDEFICS can answer questions about images, provide detailed descriptions of visual content, generate stories based on a series of images, and function as a pure language model when no visual input is provided.
PaliGemma is an advanced VLM that draws inspiration from PaLI-3 and leverages open-source components like the SigLIP vision model and the Gemma language model.
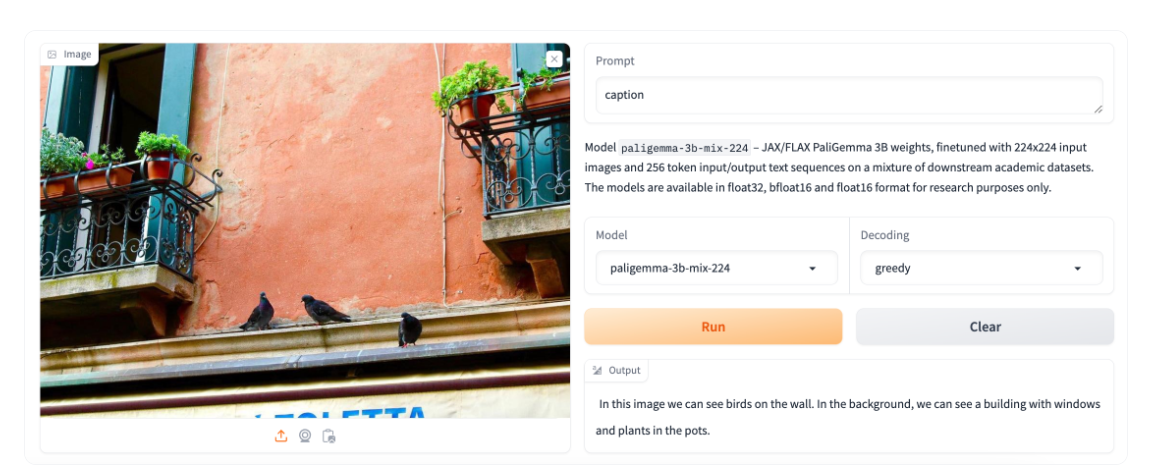
Designed to process both images and textual input, PaliGemma excels at generating descriptive text in multiple languages. Its capabilities extend to a variety of tasks, including image captioning, answering questions from visuals, reading text, detecting subjects in images, and segmenting objects displayed in images.
The core architecture of PaliGemma includes a Transformer decoder paired with a Vision Transformer image encoder that boasts an impressive 3 billion parameters. The text decoder is derived from Gemma-2B, while the image encoder is based on SigLIP-So400m/14.
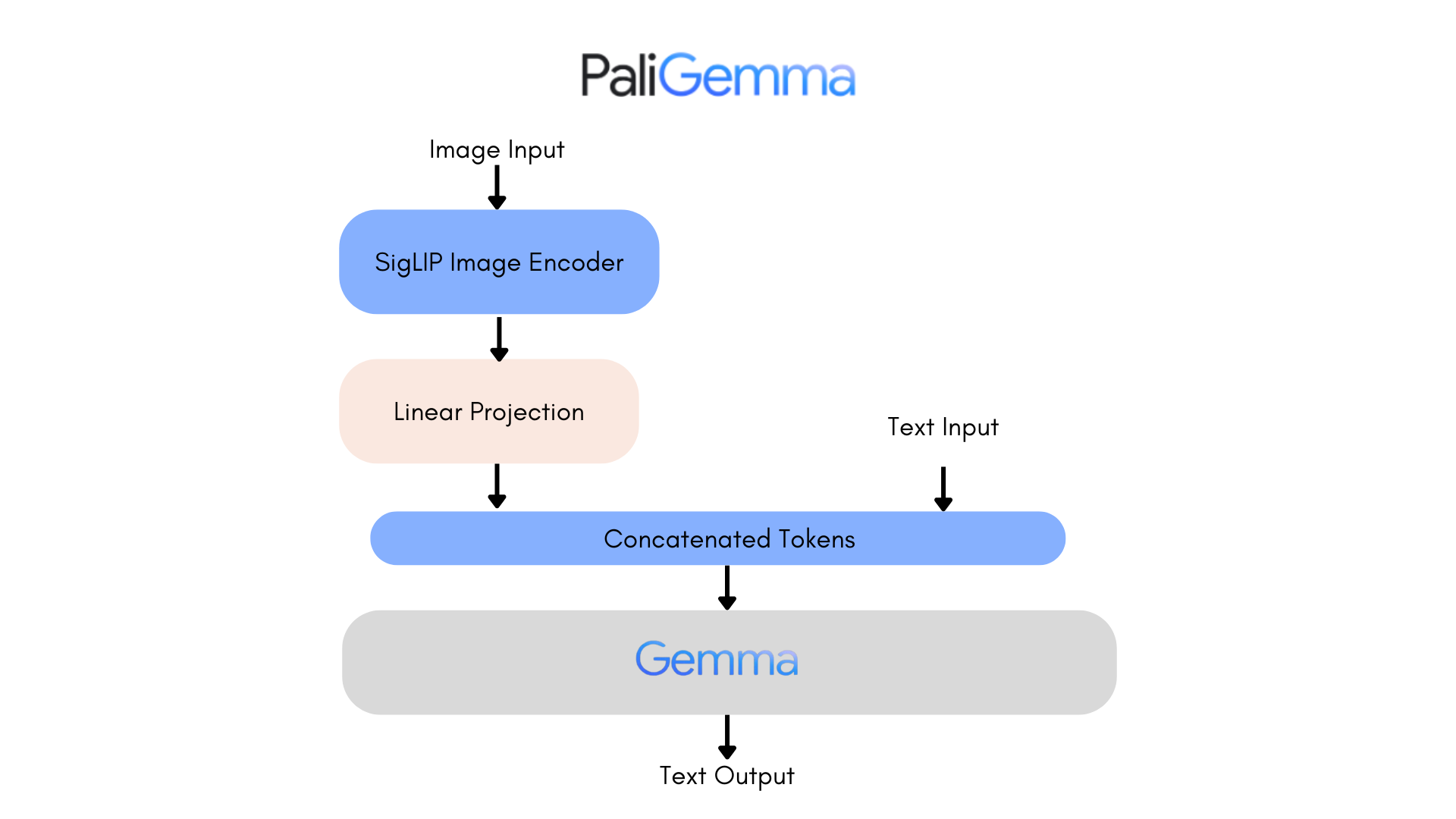
Through training methods similar to PaLI-3, PaliGemma achieves exceptional performance across numerous vision-language challenges.
PaliGemma is offered in two distinct sets:
The Phi-3-Vision-128K-Instruct model is a Microsoft-backed venture that combines text and vision capabilities. It’s built on a dataset of high-quality, reasoning-dense data from both text and visual sources. Part of the Phi-3 family, the model has a context length of 128K, making it suitable for a range of applications.
You might decide to use Phi-3-Vision-128K-Instruct in cases where your application has limited memory and computing power, thanks to its relatively lightweight that helps with latency. The model works best for generally understanding images, recognizing characters in text, and describing charts and tables.
Yi-VL is an open-source AI model developed by 01-ai that can have multi-round conversations with images by reading text from images and translating it. This model is part of the Yi LLM series and has two versions: 6B and 34B.
What distinguishes Yi-VL from other models is its ability to carry a conversation, whereas other models are typically limited to a single text input. Plus, it’s bilingual making it more versatile in a variety of language contexts.
Finding And Evaluating VLMsThere are many, many VLMs and we only looked at a few of the most notable offerings. As you commence work on an application with image-to-text capabilities, you may find yourself wondering where to look for VLM options and how to compare them.
There are two resources in the Hugging Face community you might consider using to help you find and compare VLMs. I use these regularly and find them incredibly useful in my work.
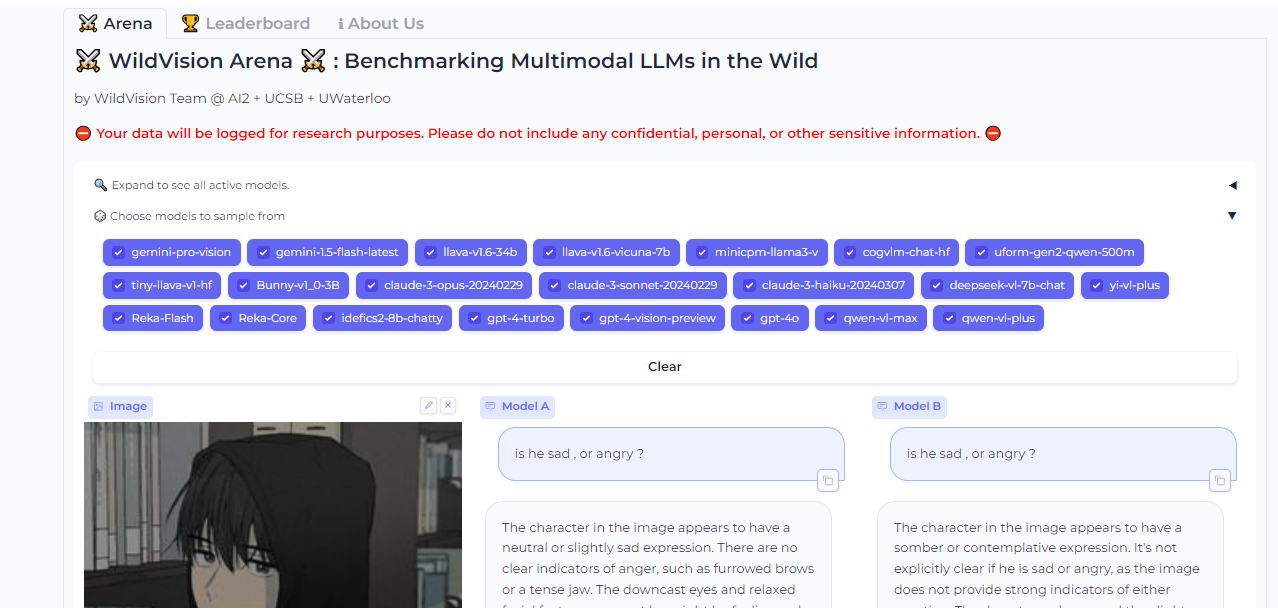
Vision Arena is a leaderboard that ranks VLMs based on anonymous user voting and reviews. But what makes it great is the fact that you can compare any two models side-by-side for yourself to find the best fit for your application.
And when you compare two models, you can contribute your own anonymous votes and reviews for others to lean on as well.
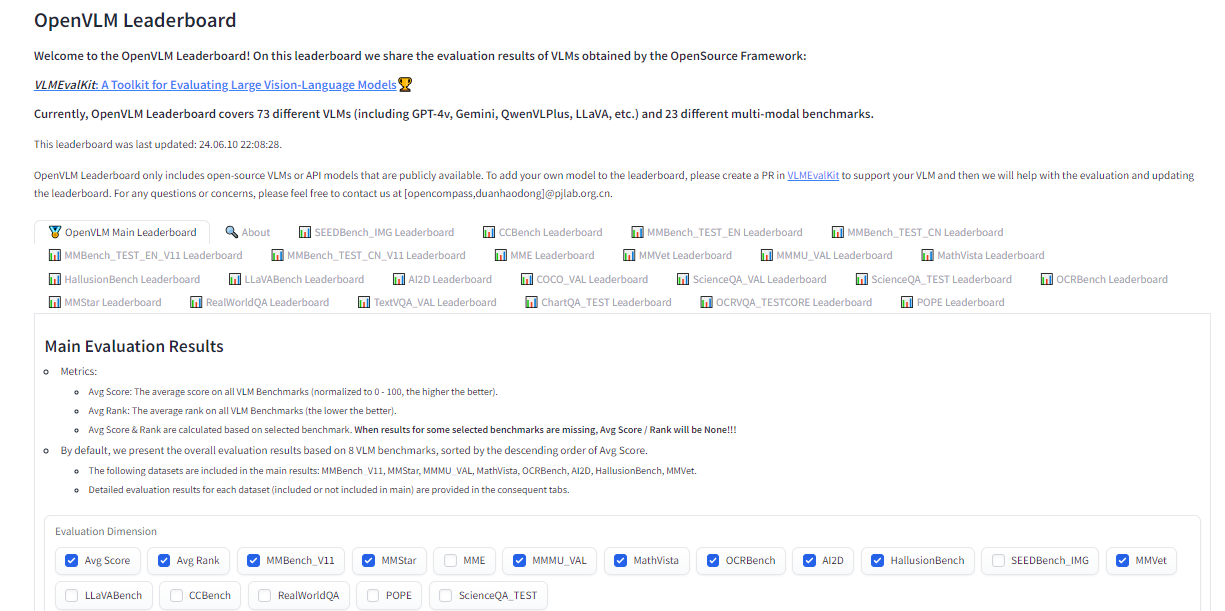
OpenVLM is another leaderboard hosted on Hugging Face for getting technical specs on different models. What I like about this resource is the wealth of metrics for evaluating VLMs, including the speed and accuracy of a given VLM.
Further, OpenVLM lets you filter models by size, type of license, and other ranking criteria. I find it particularly useful for finding VLMs I might have overlooked or new ones I haven’t seen yet.
Earlier, I mentioned that the app we are about to build will use vision-language models to generate written descriptions of images, which are then read aloud. The technology that handles converting text to audio speech is known as text-to-speech synthesis or simply text-to-speech (TTS).
TTS converts written text into synthesized speech that sounds natural. The goal is to take published content, like a blog post, and read it out loud in a realistic-sounding human voice.
So, how does TTS work? First, it breaks down text into the smallest units of sound, called phonemes, and this process allows the system to figure out proper word pronunciations. Next, AI enters the mix, including deep learning algorithms trained on hours of human speech data. This is how we get the app to mimic human speech patterns, tones, and rhythms — all the things that make for “natural” speech. The AI component is key as it elevates a voice from robotic to something with personality. Finally, the system combines the phoneme information with the AI-powered digital voice to render the fully expressive speech output.
The result is automatically generated speech that sounds fairly smooth and natural. Modern TTS systems are extremely advanced in that they can replicate different tones and voice inflections, work across languages, and understand context. This naturalness makes TTS ideal for humanizing interactions with technology, like having your device read text messages out loud to you, just like Apple’s Siri or Microsoft’s Cortana.
TTS ExamplesBased on the use cases we covered alone, you can probably imagine that VLMs come in many forms, each with its unique strengths and applications. In this section, we will look at a few examples of VLMs that can be used for a variety of different purposes.
Just as we took a moment to review existing vision language models, let’s pause to consider some of the more popular TTS resources that are available.
Straight from Bark’s model card in Hugging Face:
“Bark is a transformer-based text-to-audio model created by Suno. Bark can generate highly realistic, multilingual speech as well as other audio — including music, background noise, and simple sound effects. The model can also produce nonverbal communication, like laughing, sighing, and crying. To support the research community, we are providing access to pre-trained model checkpoints ready for inference.”
The non-verbal communication cues are particularly interesting and a distinguishing feature of Bark. Check out the various things Bark can do to communicate emotion, pulled directly from the model’s GitHub repo:
[laughter][laughs][sighs][music][gasps][clears throat]This could be cool or creepy, depending on how it’s used, but reflects the sophistication we’re working with. In addition to laughing and gasping, Bark is different in that it doesn’t work with phonemes like a typical TTS model:
“It is not a conventional TTS model but instead a fully generative text-to-audio model capable of deviating in unexpected ways from any given script. Different from previous approaches, the input text prompt is converted directly to audio without the intermediate use of phonemes. It can, therefore, generalize to arbitrary instructions beyond speech, such as music lyrics, sound effects, or other non-speech sounds.”
Coqui/XTTS-v2 can clone voices in different languages. All it needs for training is a short six-second clip of audio. This means the model can be used to translate audio snippets from one language into another while maintaining the same voice.
At the time of writing, Coqui currently supports 16 languages, including English, Spanish, French, German, Italian, Portuguese, Polish, Turkish, Russian, Dutch, Czech, Arabic, Chinese, Japanese, Hungarian, and Korean.
Parler-TTS excels at generating high-quality, natural-sounding speech in the style of a given speaker. In other words, it replicates a person’s voice. This is where many folks might draw an ethical line because techniques like this can be used to essentially imitate a real person, even without their consent, in a process known as “deepfake” and the consequences can range from benign impersonations to full-on phishing attacks.
But that’s not really the aim of Parler-TTS. Rather, it’s good in contexts that require personalized and natural-sounding speech generation, such as voice assistants and possibly even accessibility tooling to aid visual impairments by announcing content.
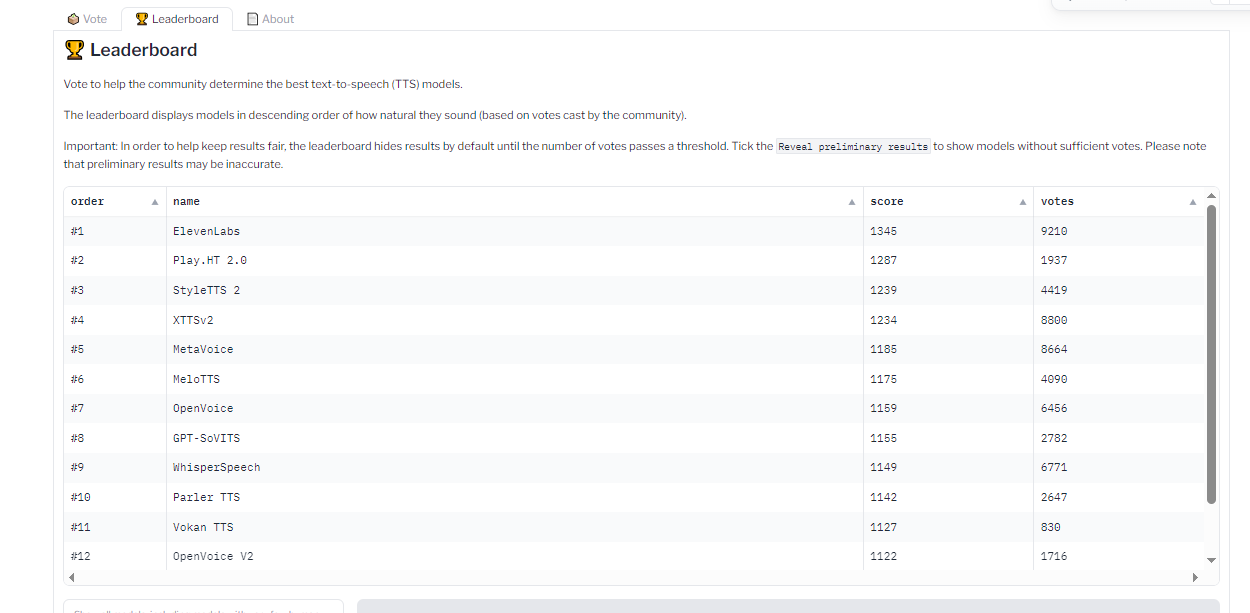
Do you know how I shared the OpenVLM Leaderboard for finding and comparing vision language models? Well, there’s an equivalent leadership for TTS models as well over at the Hugging Face community called TTS Arena.
TTS models are ranked by the “naturalness” of their voices, with the most natural-sounding models ranked first. Developers like you and me vote and provide feedback that influences the rankings.
What we just looked at are TTS models that are baked into whatever app we’re making. However, some models are consumable via API, so it’s possible to get the benefits of a TTS model without the added bloat if a particular model is made available by an API provider.
Whether you decide to bundle TTS models in your app or integrate them via APIs is totally up to you. There is no right answer as far as saying one method is better than another — it’s more about the app’s requirements and whether the dependability of a baked-in model is worth the memory hit or vice-versa.
All that being said, I want to call out a handful of TTS API providers for you to keep in your back pocket.
ElevenLabs offers a TTS API that uses neural networks to make voices sound natural. Voices can be customized for different languages and accents, leading to realistic, engaging voices.
Try the model out for yourself on the ElevenLabs site. You can enter a block of text and choose from a wide variety of voices that read the submitted text aloud.
Colossyan’s text-to-speech API converts text into natural-sounding voice recordings in over 70 languages and accents. From there, the service allows you to match the audio to an avatar to produce something like a complete virtual presentation based on your voice — or someone else’s.
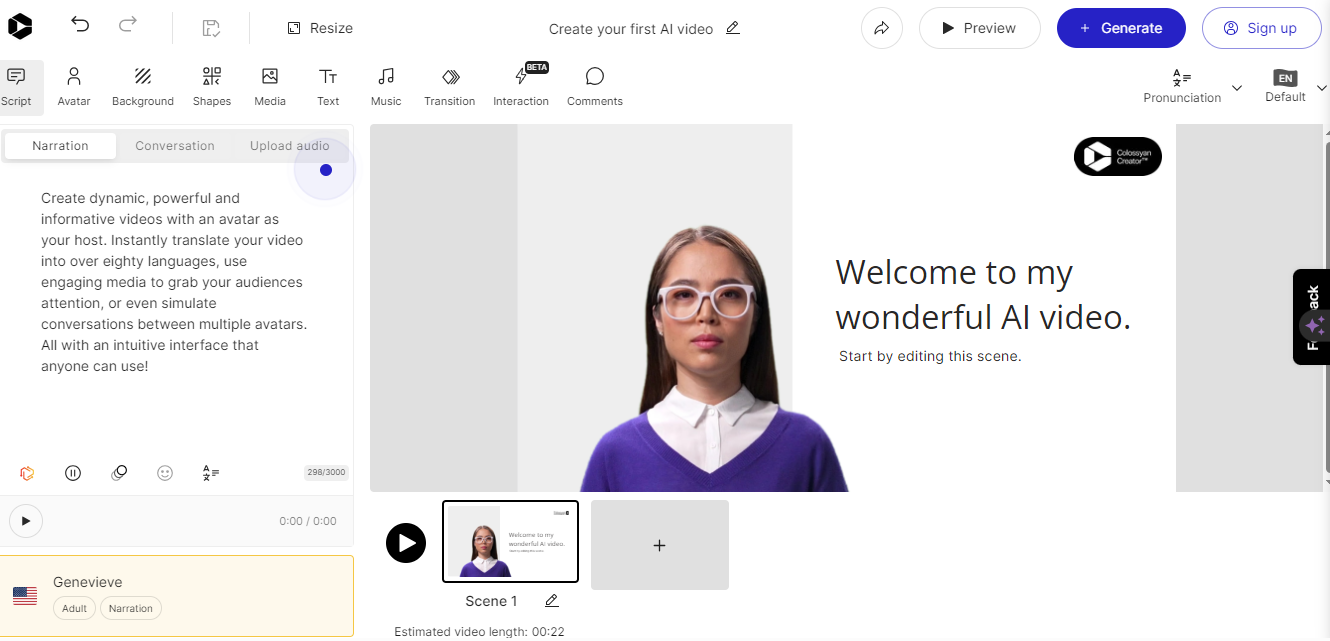
Once again, this is encroaching on deepfake territory, but it’s really interesting to think of Colossyan’s service as a virtual casting call for actors to perform off a script.
Murf.ai is yet another TTS API designed to generate voiceovers based on real human voices. The service provides a slew of premade voices you can use to generate audio for anything from explainer videos and audiobooks to course lectures and entire podcast episodes.

Amazon has its own TTS API called Polly. You can customize the voices using lexicons and Speech Synthesis Markup (SSML) tags for establishing speaking styles with affordances for adjusting things like pitch, speed, and volume.
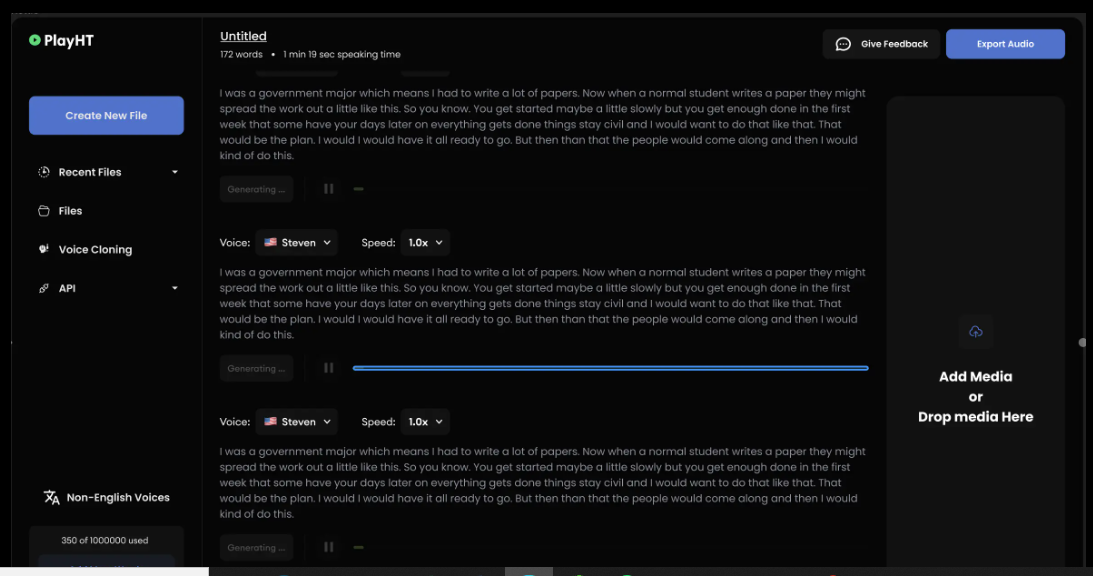
The PlayHT TTS API generates speech in 142 languages. Type what you want it to say, pick a voice, and download the output as an MP3 or WAV file.
So far, we have discussed the two primary components for generating audio from text: vision-language models and text-to-speech models. We’ve covered what they are, where they fit into the process of generating real-sounding speech, and various examples of each model.
Now, it’s time to apply those concepts to the app we are building in this tutorial (and will improve in a second tutorial). We will use a VLM so the app can glean meaning and context from images, a TTS model to generate speech that mimics a human voice, and then integrate our work into a user interface for submitting images that will lead to generated speech output.
I have decided to base our work on a VLM by Salesforce called BLIP, a TTS model from Kakao Enterprise called VITS, and Gradio as a framework for the design interface. I’ve covered Gradio extensively in other articles, but the gist is that it is a Python library for building web interfaces — only it offers built-in tools for working with machine learning models that make Gradio ideal for a tutorial like this.
You can use completely different models if you like. The whole point is less about the intricacies of a particular model than it is to demonstrate how the pieces generally come together.
Oh, and one more detail worth noting: I am working with the code for all of this in Google Collab. I’m using it because it’s hosted and ideal for demonstrations like this. But you can certainly work in a more traditional IDE, like VS Code.
First, we need to install the necessary libraries:
#python
!pip install gradio pillow transformers scipy numpy
We can upgrade the transformers library to the latest version if we need to:
#python
!pip install --upgrade transformers
Not sure if you need to upgrade? Here’s how to check the current version:
#python
import transformers
print(transformers.__version__)
OK, now we are ready to import the libraries:
#python
import gradio as gr
from PIL import Image
from transformers import pipeline
import scipy.io.wavfile as wavfile
import numpy as np
These libraries will help us process images, use models on the Hugging Face hub, handle audio files, and build the UI.
Since we will pull our models directly from Hugging Face’s model hub, we can tap into them using pipelines. This way, we’re working with an API for tasks that involve natural language processing and computer vision without carrying the load in the app itself.
We set up our pipeline like this:
#python
caption_image = pipeline("image-to-text", model="Salesforce/blip-image-captioning-large")
This establishes a pipeline for us to access BLIP for converting images into textual descriptions. Again, you could establish a pipeline for any other model in the Hugging Face hub.
We’ll need a pipeline connected to our TTS model as well:
#python
Narrator = pipeline("text-to-speech", model="kakao-enterprise/vits-ljs")
Now, we have a pipeline where we can pass our image text to be converted into natural-sounding speech.
What we need now is a function that handles the audio conversion. Your code will differ depending on the TTS model in use, but here is how I approached the conversion based on the VITS model:
#python
def generate_audio(text):
# Generate speech from the input text using the Narrator (VITS model)
Narrated_Text = Narrator(text)
# Extract the audio data and sampling rate
audio_data = np.array(Narrated_Text["audio"][0])
sampling_rate = Narrated_Text["sampling_rate"]
# Save the generated speech as a WAV file
wavfile.write("generated_audio.wav", rate=sampling_rate, data=audio_data)
# Return the filename of the saved audio file
return "generated_audio.wav"
That’s great, but we need to make sure there’s a bridge that connects the text that the app generates from an image to the speech conversion. We can write a function that uses BLIP to generate the text and then calls the generate_audio() function we just defined:
#python
def caption_my_image(pil_image):
# Use BLIP to generate a text description of the input image
semantics = caption_image(images=pil_image)[0]["generated_text"]
# Generate audio from the text description
return generate_audio(semantics)
Our app would be pretty useless if there was no way to interact with it. This is where Gradio comes in. We will use it to create a form that accepts an image file as an input and then outputs the generated text for display as well as the corresponding file containing the speech.
#python
main_tab = gr.Interface(
fn=caption_my_image,
inputs=[gr.Image(label="Select Image", type="pil")],
outputs=[gr.Audio(label="Generated Audio")],
title=" Image Audio Description App",
description="This application provides audio descriptions for images."
)
# Information tab
info_tab = gr.Markdown("""
# Image Audio Description App
### Purpose
This application is designed to assist visually impaired users by providing audio descriptions of images. It can also be used in various scenarios such as creating audio captions for educational materials, enhancing accessibility for digital content, and more.
### Limits
- The quality of the description depends on the image clarity and content.
- The application might not work well with images that have complex scenes or unclear subjects.
- Audio generation time may vary depending on the input image size and content.
### Note
- Ensure the uploaded image is clear and well-defined for the best results.
- This app is a prototype and may have limitations in real-world applications.
""")
# Combine both tabs into a single app
demo = gr.TabbedInterface(
[main_tab, info_tab],
tab_names=["Main", "Information"]
)
demo.launch()
The interface is quite plain and simple, but that’s OK since our work is purely for demonstration purposes. You can always add to this for your own needs. The important thing is that you now have a working application you can interact with.
At this point, you could run the app and try it in Google Collab. You also have the option to deploy your app, though you’ll need hosting for it. Hugging Face also has a feature called Spaces that you can use to deploy your work and run it without Google Collab. There’s even a guide you can use to set up your own Space.
Here’s the final app that you can try by uploading your own photo:
Coming Up…We covered a lot of ground in this tutorial! In addition to learning about VLMs and TTS models at a high level, we looked at different examples of them and then covered how to find and compare models.
But the rubber really met the road when we started work on our app. Together, we made a useful tool that generates text from an image file and then sends that text to a TTS model to convert it into speech that is announced out loud and downloadable as either an MP3 or WAV file.
But we’re not done just yet! What if we could glean even more detailed information from images and our app not only describes the images but can also carry on a conversation about them?
Sounds exciting, right? This is exactly what we’ll do in the second part of this tutorial.

There are many rumors and misconceptions about conforming to WCAG criteria for the minimum sizing of interactive elements. I’d like to use this post to demystify what is needed for baseline compliance and to point out an approach for making successful and inclusive interactive experiences using ample target sizes.
Minimum Conformant Pixel SizeGetting right to it: When it comes to pure Web Content Accessibility Guidelines (WCAG) conformance, the bare minimum pixel size for an interactive, non-inline element is 24×24 pixels. This is outlined in Success Criterion 2.5.8: Target Size (Minimum).

Success Criterion 2.5.8 is level AA, which is the most commonly used level for public, mass-consumed websites. This Success Criterion (or SC for short) is sometimes confused for SC 2.5.5 Target Size (Enhanced), which is level AAA. The two are distinct and provide separate guidance for properly sizing interactive elements, even if they appear similar at first glance.
SC 2.5.8 is relatively new to WCAG, having been released as part of WCAG version 2.2, which was published on October 5th, 2023. WCAG 2.2 is the most current version of the standard, but this newer release date means that knowledge of its existence isn’t as widespread as the older SC, especially outside of web accessibility circles. That said, WCAG 2.2 will remain the standard until WCAG 3.0 is released, something that is likely going to take 10–15 years or more to happen.
SC 2.5.5 calls for larger interactive elements sizes that are at least 44×44 pixels (compared to the SC 2.5.8 requirement of 24×24 pixels). At the same time, notice that SC 2.5.5 is level AAA (compared to SC 2.5.8, level AA) which is a level reserved for specialized support beyond level AA.

Sites that need to be fully WCAG Level AAA conformant are rare. Chances are that if you are making a website or web app, you’ll only need to support level AA. Level AAA is often reserved for large or highly specialized institutions.
The family of padding-related properties in CSS can be used to extend the interactive area of an element to make it conformant. For example, declaring padding: 4px; on an element that measures 16×16 pixels invisibly increases its bounding box to a total of 24×24 pixels. This, in turn, means the interactive element satisfies SC 2.5.8.

This is a good trick for making smaller interactive elements easier to click and tap. If you want more information about this sort of thing, I enthusiastically recommend Ahmad Shadeed’s post, “Designing better target sizes”.
I think it’s also worth noting that CSS margin could also hypothetically be used to achieve level AA conformance since the SC includes a spacing exception:
The size of the target for pointer inputs is at least 24×24 CSS pixels, except where:
Spacing: Undersized targets (those less than 24×24 CSS pixels) are positioned so that if a 24 CSS pixel diameter circle is centered on the bounding box of each, the circles do not intersect another target or the circle for another undersized target;
[…]
The difference here is that padding extends the interactive area, while margin does not. Through this lens, you’ll want to honor the spirit of the success criterion because partial conformance is adversarial conformance. At the end of the day, we want to help people successfully click or tap interactive elements, such as buttons.
We tend to think of targets in terms of block elements — elements that are displayed on their own line, such as a button at the end of a call-to-action. However, interactive elements can be inline elements as well. Think of links in a paragraph of text.
Inline interactive elements, such as text links in paragraphs, do not need to meet the 24×24 pixel minimum requirement. Just as margin is an exception in SC 2.5.8: Target Size (Minimum), so are inline elements with an interactive target:
The size of the target for pointer inputs is at least 24×24 CSS pixels, except where:
[…]
Inline: The target is in a sentence or its size is otherwise constrained×the line-height of non-target text;
[…]

If the differences between interactive elements that are inline and block are still confusing, that’s probably because the whole situation is even further muddied by third-party human interface guidelines requiring interactive sizes closer to what the level AAA Success Criterion 2.5.5 Target Size (Enhanced) demands.
For example, Apple’s “Human Interface Guidelines” and Google’s “Material Design” are guidelines for how to design interfaces for their respective platforms. Apple’s guidelines recommend that interactive elements are 44×44 points, whereas Google’s guides stipulate target sizes that are at least 48×48 using density-independent pixels.
These may satisfy Apple and Google requirements for designing interfaces, but are they WCAG-conformant Apple and Google — not to mention any other organization with UI guidelines — can specify whatever interface requirements they want, but are they copasetic with WCAG SC 2.5.5 and SC 2.5.8?
It’s important to ask this question because there is a hierarchy when it comes to accessibility compliance, and it contains legal levels:

Human interface guidelines often inform design systems, which, in turn, influence the sites and apps that are built by authors like us. But they’re not the “authority” on accessibility compliance. Notice how everything is (and ought to be) influenced by WCAG at the very top of the chain.
Even if these third-party interface guidelines conform to SC 2.5.5 and 2.5.8, it’s still tough to tell when they are expressed in “points” and “density independent pixels” which aren’t pixels, but often get conflated as such. I’d advise not getting too deep into researching what a pixel truly is-pixel%3F). Trust me when I say it’s a road you don’t want to go down. But whatever the case, the inconsistent use of unit sizes exacerbates the issue.
Can’t We Just Use A Media Query?I’ve also observed some developers attempting to use the pointer media feature as a clever “trick” to detect when a touchscreen is present, then conditionally adjust an interactive element’s size as a way to get around the WCAG requirement.

After all, mouse cursors are for fine movements, and touchscreens are for more broad gestures, right? Not always. The thing is, devices are multimodal. They can support many different kinds of input and don’t require a special switch to flip or button to press to do so. A straightforward example of this is switching between a trackpad and a keyboard while you browse the web. A less considered example is a device with a touchscreen that also supports a trackpad, keyboard, mouse, and voice input.
You might think that the combination of trackpad, keyboard, mouse, and voice inputs sounds like some sort of absurd, obscure Frankencomputer, but what I just described is a Microsoft Surface laptop, and guess what? They’re pretty popular.

There is a difference between the two, even though they are often used interchangeably. Let’s delineate the two as clearly as possible:
The other end of this consideration is that people with motor control conditions — like hand tremors or arthritis — can and do use mice inputs. This means that fine input actions may be painful and difficult, yet ultimately still possible to perform.
People also use more precise input mechanisms for touchscreens all the time, including both official accessories and aftermarket devices. In other words, some devices designed to accommodate coarse input can also be used for fine detail work.
I’d be remiss if I didn’t also point out that people plug mice and keyboards into smartphones. We cannot automatically say that they only support coarse pointers:

Conformant and successful interactive areas — both large and small — require knowing the ultimate goals of your website or web app. When you arm yourself with this context, you are empowered to make informed decisions about the kinds of people who use your service, why they use the service, and how you can accommodate them.
For example, the Glow Baby app uses larger interactive elements because it knows the user is likely holding an adorable, albeit squirmy and fussy, baby while using the application. This allows Glow Baby to emphasize the interactive targets in the interface to accommodate parents who have their hands full.

In the same vein, SC SC 2.5.8 acknowledges that smaller touch targets — such as those used in map apps — may contextually be exempt:
For example, in digital maps, the position of pins is analogous to the position of places shown on the map. If there are many pins close together, the spacing between pins and neighboring pins will often be below 24 CSS pixels. It is essential to show the pins at the correct map location; therefore, the Essential exception applies.
[…]
When the "Essential" exception is applicable, authors are strongly encouraged to provide equivalent functionality through alternative means to the extent practical.
Note that this exemption language is not carte blanche to make your own work an exception to the rule. It is more of a mechanism, and an acknowledgment that broadly applied rules may have exceptions that are worth thinking through and documenting for future reference.
Further ConsiderationsWe also want to consider the larger context of the device itself as well as the environment the device will be used in.
Larger, more fixed position touchscreens compel larger interactive areas. Smaller devices that are moved around in space a lot (e.g., smartwatches) may benefit from alternate input mechanisms such as voice commands.
What about people who are driving in a car? People in this context probably ought to be provided straightforward, simple interactions that are facilitated via large interactive areas to prevent them from taking their eyes off the road. The same could also be said for high-stress environments like hospitals and oil rigs.
Similarly, devices and apps that are designed for children may require interactive areas that are larger than WCAG requirements for interactive areas. So would experiences aimed at older demographics, where age-derived vision and motor control disability factors tend to be more present.
Minimum conformant interactive area experiences may also make sense in their own contexts. Data-rich, information-dense experiences like the Bloomberg terminal come to mind here.
Design Systems Are Also Worth NotingWhile you can control what components you include in a design system, you cannot control where and how they’ll be used by those who adopt and use that design system. Because of this, I suggest defensively baking accessible defaults into your design systems because they can go a long way toward incorporating accessible practices when they’re integrated right out of the box.
One option worth consideration is providing an accessible range of choices. Components, like buttons, can have size variants (e.g., small, medium, and large), and you can provide a minimally conformant interactive target on the smallest variant and then offer larger, equally conformant versions.

There is no magic number or formula to get you that perfect Goldilocks “not too small, not too large, but just right” interactive area size. It requires knowledge of what the people who want to use your service want, and how they go about getting it.
The best way to learn that? Ask people.
Accessibility research includes more than just asking people who use screen readers what they think. It’s also a lot easier to conduct than you might think! For example, prototypes are a great way to quickly and inexpensively evaluate and de-risk your ideas before committing to writing production code. “Conducting Accessibility Research In An Inaccessible Ecosystem” by Dr. Michele A. Williams is chock full of tips, strategies, and resources you can use to help you get started with accessibility research.
Wrapping UpThe bottom line is that
“Compliant” does not always equate to “usable.” But compliance does help set baseline requirements that benefit everyone.
To sum things up:
And, perhaps most importantly, all of this is about people and enabling them to get what they need.

 WordPress 6.6 “Dorsey” went live a couple of days ago on July 16! As with most of the major releases over the past few years, the new features and changes primarily focus on the Site Editor and Block Editor, with not much being done for people using the “classic” approach to WordPress.
WordPress 6.6 “Dorsey” went live a couple of days ago on July 16! As with most of the major releases over the past few years, the new features and changes primarily focus on the Site Editor and Block Editor, with not much being done for people using the “classic” approach to WordPress. 
This article is a sponsored by Penpot
If you’ve been following along with our Penpot series, you’re already familiar with this exciting open-source design tool and how it is changing the game for designer-developer collaboration. Previously, we’ve explored Penpot’s Flex Layout and Grid Layout features, which bring the power of CSS directly into the hands of designers.
Today, we’re diving into another crucial aspect of modern web design and development: components. This feature is a part of Penpot’s major 2.0 release, which introduces a host of new capabilities to bridge the gap between design and code further. Let’s explore how Penpot’s implementation of components can supercharge your design workflow and foster even better collaboration across teams.
About ComponentsComponents are reusable building blocks that form the foundation of modern user interfaces. They encapsulate a piece of UI or functionality that can be reused across your application. This concept of composability — building complex systems from smaller, reusable parts — is a cornerstone of modern web development.
Why does composability matter? There are several key benefits:
In the realm of design, this philosophy is best expressed in the concept of design systems. When done right, design systems help to bring your design and code together, reducing ambiguity and streamlining the processes.
However, that’s not so easy to achieve when your designs are built using logic and standards that are much different from the code they’re related to. Penpot works to solve this challenge through its unique approach. Instead of building visual artifacts that only mimic real-world interfaces, UIs in Penpots are built using the same technologies and standards as real working products.
This gives us much better parity between the media and allows designers to build interfaces that are already expressed as code. It fosters easier collaboration as designers and developers can speak the same language when discussing their components. The final result is more maintainable, too. Changes created by designers can propagate consistently, making it easier to manage large-scale systems.
Now, let’s take a look at how components in Penpot work in practice! As an example, I’m going to use the following fictional product page and recreate it in Penpot:

To create a component in Penpot, simply select the objects you want to include and select “Create component” from the context menu. This transforms your selection into a reusable element.
Penpot allows you to create variants of your components. These are alternative versions that share the same basic structure but differ in specific aspects like color, size, or state.
You can create variants by using slashes (/) in the components name, for example, by naming your buttons Button/primary and Button/secondary. This will allow you to easily switch between types of a Button component later.
Components in Penpot can be nested, allowing you to build complex UI elements from simpler parts. This mirrors how developers often structure their code. In other words, you can place components inside one another.
Moreover, the components you use don’t have to come from the same file or even from the same organization. You can easily share libraries of components across projects just as you would import code from various dependencies into your codebase. You can also import components from external libraries, such as UI kits and icon sets. Penpot maintains a growing list of such resources for you to choose from, including everything from the large design systems like Material Design to the most popular icon libraries.
The new major release of Penpot comes with a redesigned Assets panel, which is where your components live. In the Assets panel, you can easily access your components and drag and drop them into designs.
For the better maintenance of design systems, Penpot allows you to store your colors and typography as reusable styles. Same as components, you can name your styles and organize them into hierarchical structures.
One of the main benefits of using composable components in front-end libraries such as React is their support of props. Component props (short for properties) allow you a great deal of flexibility in how you configure and customize your components, depending on how, where, and when they are used.
Penpot offers similar capabilities in a design tool with variants and overrides. You can switch variants, hide elements, change styles, swap nested components within instances, or even change the whole layout of a component, providing flexibility while maintaining the link to the original component.
Allowing you to modify Flex and Grid layouts in component instances is where Penpot really shines. However, the power of these layout features goes beyond the components themselves.
With Flex Layout and Grid Layout, you can build components that are much more faithful to their code and easier to modify and maintain. But having those powerful features at your fingertips means that you can also place your components in other Grid and Flex layouts. That’s a big deal as it allows you to test your components in scenarios much closer to their real environment. Directly in a design tool, you can see how your component would behave if you put it in various places on your website or app. This allows you to fine-tune how your components fit into a larger system. It can dramatically reduce friction between design and code and streamline the handoff process.
As Penpot’s components are just web-ready code, one of the greatest benefits of using it is how easily you can export code for your components. This feature, like all of Penpot’s capabilities, is completely free.
Using Penpot’s Inspect panel, you can quickly grab all the layout properties and styles as well as the full code snippets for all components.
To make design systems in Penpot even more maintainable, it includes annotation features to help you document your components. This is crucial for maintaining a clear design system and ensuring a smooth handoff to developers.
SummaryPenpot’s implementation of components and its support for real CSS layouts make it a standout tool for designers who want to work closely with developers. By embracing web standards and providing powerful, flexible components, Penpot enables designers to create more developer-friendly designs without sacrificing creativity or control.
All of Penpot’s features are completely free for both designers and developers. As open-source software, Penpot lets you fully own your design tool experience and makes it accessible for everyone, regardless of team size and budget.
Ready to dive in? You can explore the file used in this article by downloading it and importing into your Penpot account.
As the design tool landscape continues to evolve, Penpot is taking charge of bringing designers and developers closer together. Whether you’re a designer looking to understand the development process or a developer seeking to streamline your workflow with designers, Penpot’s component system is worth exploring.